Building a Newspaper-Like Feed for Hacker News
Last month, I shared 'Your Hacker News' on Hacker News. The project tackled two improvements I wanted for HN: previewing content and showing more relevant stories.
The Why
When browsing Hacker News, I don't get a good idea of whether I'll like an article or not from the title. But I know for sure after reading a few paragraphs. Your Hacker News tries to solve this by showing you a snippet and an image from the article.
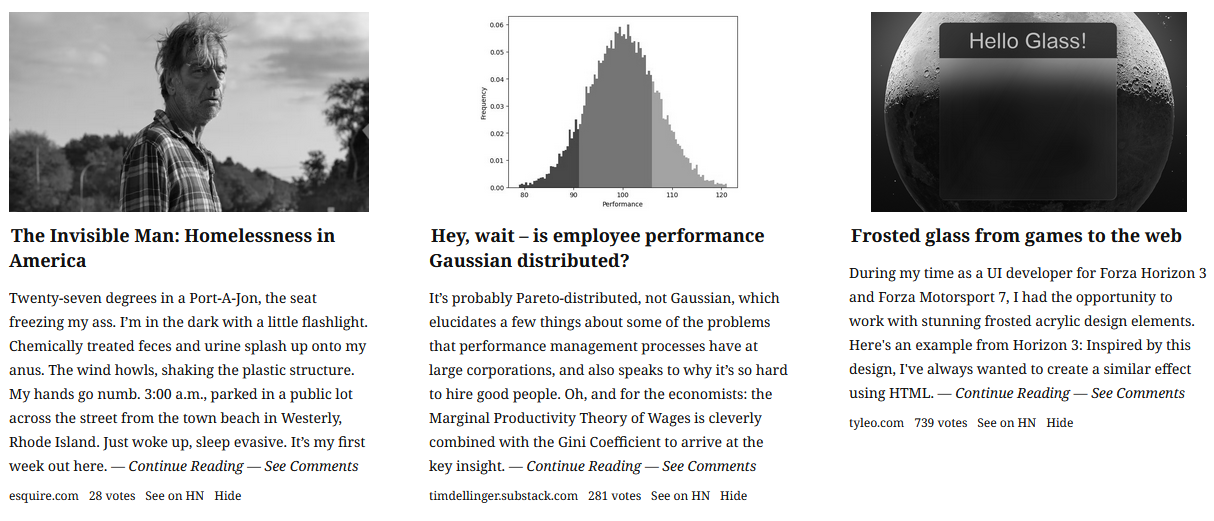
The design drew inspiration from traditional newspapers, but several users pointed out that it's not the same. Print newspapers have visual hierarchy and are manually curated, with editors carefully placing chosen images and headlines.

Since our frontpage is automatically generated, my attempts to emulate a newspaper-style layout didn't look very good.

I could've improved it, dividing content into columns, filling in whitespace etc. But I realized it would take too much time, and I decided to go with a feed-like design and focus on adding personalization.
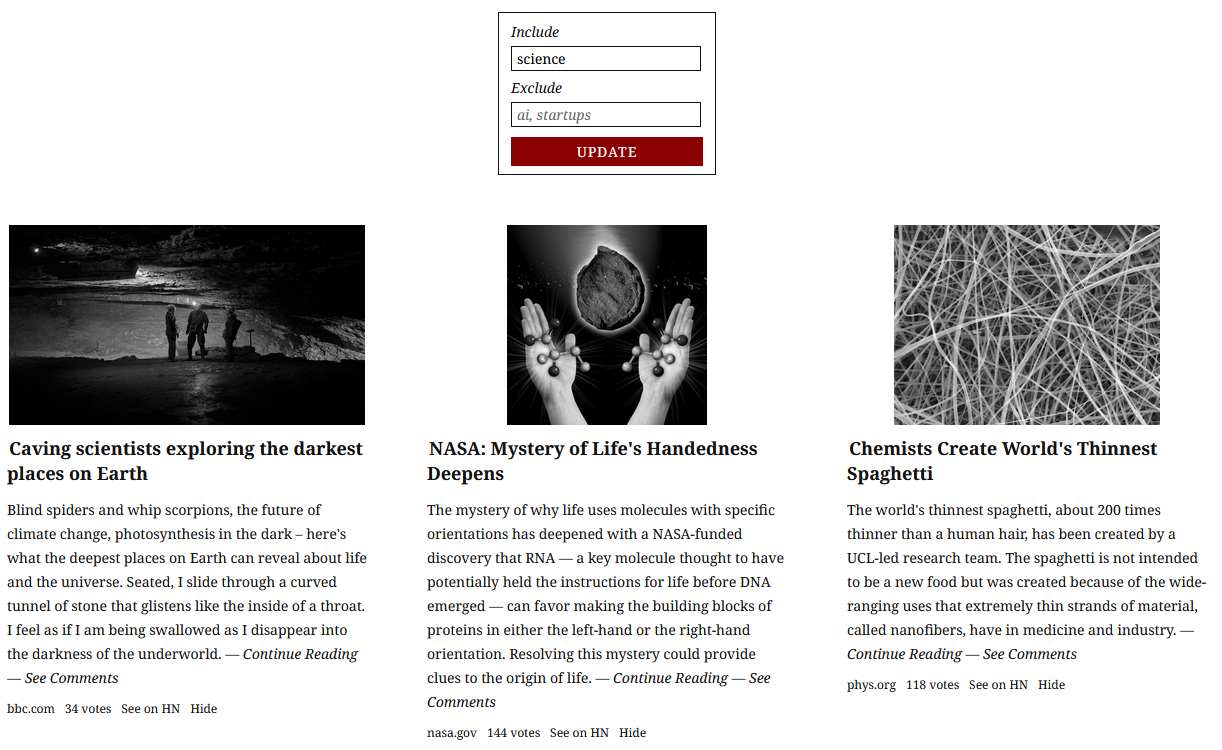
How It Works
The app starts by fetching the top 150 stories from the Hacker News API. For each story, Puppeteer retrieves the HTML content and then GPT-4o-mini extracts a snippet of the content:
const response = await this.openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "system",
content: `You are a content extraction assistant. Your task is to extract the main content from a website's text.
Provide the first 500 or fewer characters of the relevant content as is. Don't get any metadata or author information.
If no content can be extracted or it's in another format, return an empty string.`
},
{
role: "user",
content: bodyText
}
],
max_tokens: 500,
temperature: 0.1
});This works well to strip away unnecessary text, like metadata and navigation menus, only failing in a few cases like websites that implement captchas or paywalls. The snippet is skipped for those stories.
Next, it personalizes your feed. This started with like/dislike buttons next to each story, but that turned out to be a bit limiting. I switched to using keywords, where you enter what to include or exclude e.g, 'AI', 'Math' etc. To check similarity, it converts keywords and stories to embeddings (which are basically numerical representations or vectors of text):
async generateEmbeddingForStory(title, content) {
const combinedText = `Title: ${title}\nContent: ${content}`.trim()
const response = await openai.embeddings.create({
model: "text-embedding-3-small",
input: combinedText.substring(0, 900)
})
return response.data[0].embedding
}It then compares the embeddings using cosine similarity, which measures how alike two texts are by comparing the angle between their vectors:
function calculateCosineSimilarity(embedding1, embedding2) {
const dotProduct = embedding1.reduce((sum, val, i) =>
sum + val * embedding2[i], 0
)
const magnitude1 = Math.sqrt(
embedding1.reduce((sum, val) => sum + val * val, 0)
)
const magnitude2 = Math.sqrt(
embedding2.reduce((sum, val) => sum + val * val, 0)
)
return dotProduct / (magnitude1 * magnitude2)
}This gives us a score for how similar or dissimilar a story is to the keywords you've chosen. The results are then sorted by a weighted score of similarity, dissimilarity and the original position.
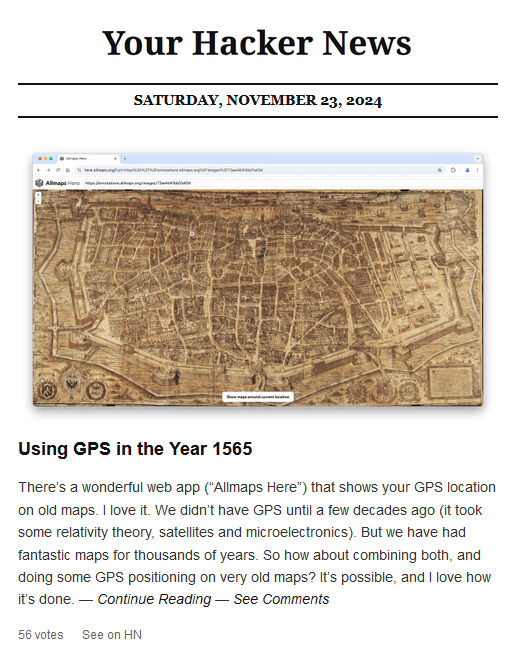
Adding a Daily Digest
Since we are a "newspaper", why not have a morning delivery? I added a subscribe option that, at 9 am EST every day, gets the top 15 stories most similar to your keywords and emails them to you. The limitations of HTML in email would need its own article, but I settled on this design:
Final Thoughts
I hope this helps you discover more stories you like on HN. I'm planning to add more features, like turning it into a PWA, getting snippets from PDFs and generating weekly digests.